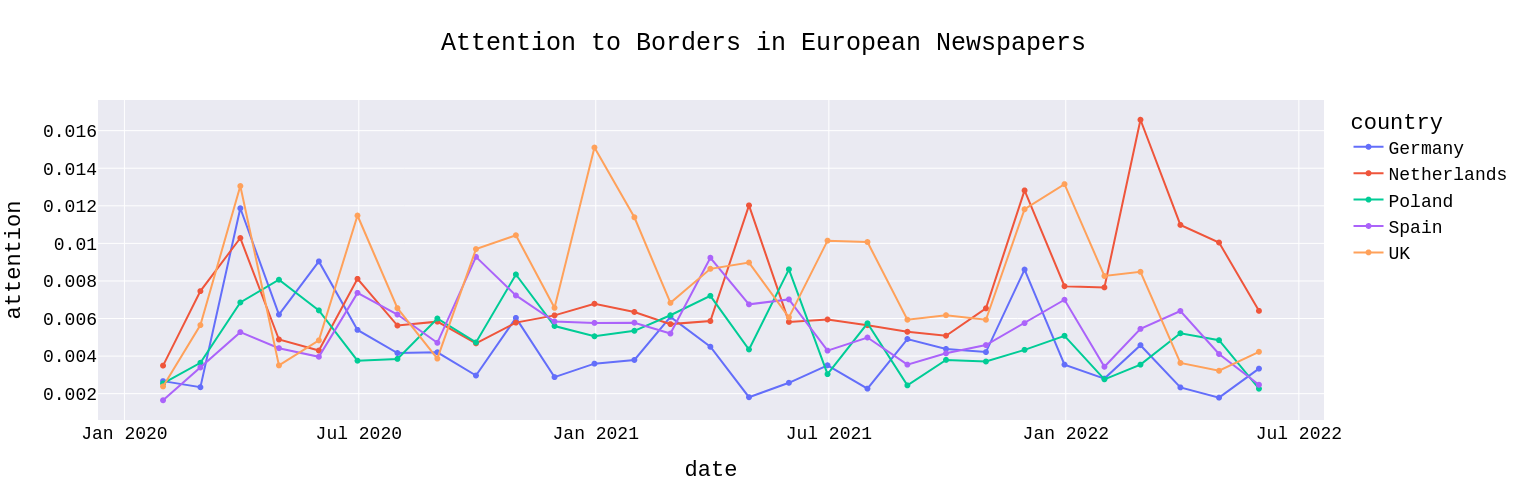
models & data
Language models and datasets I have built and released.
Language Models
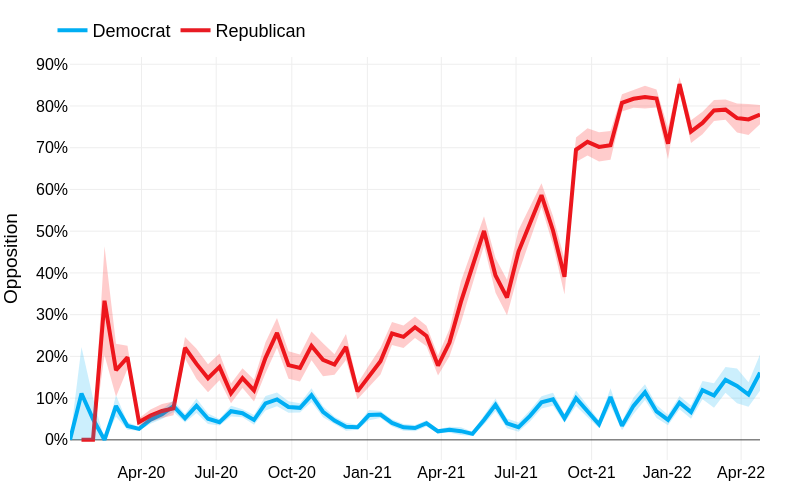
Facebook bart-large-cnn — sequence-to-sequence model trained to summarise policy positions from party press releases
Available at: z-dickson/bart-large-cnn-climate-change-summarization
Details
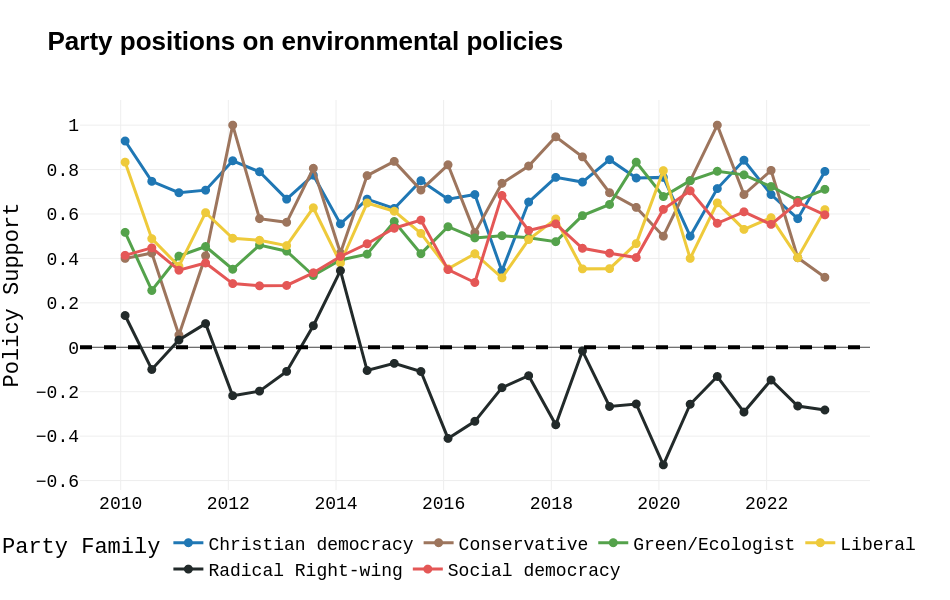
vinai/bertweet-large — model trained to predict opposition to COVID-19 policies in US congressmembers’ tweets
Available at: z-dickson/US_politicians_covid_skepticism
Details
bert-base-multilingual-cased — trained to predict the CAP issue codes of political text (bills, speeches, tweets, etc.)
Available at: z-dickson/CAP_multilingual
Details
Language model trained to predict the CAP Issue Code of political text. The model was trained on the universe of coded data from the Comparative Agendas Project (huge thanks!) and can accurately predict the CAP code of political text in multiple languages and domains.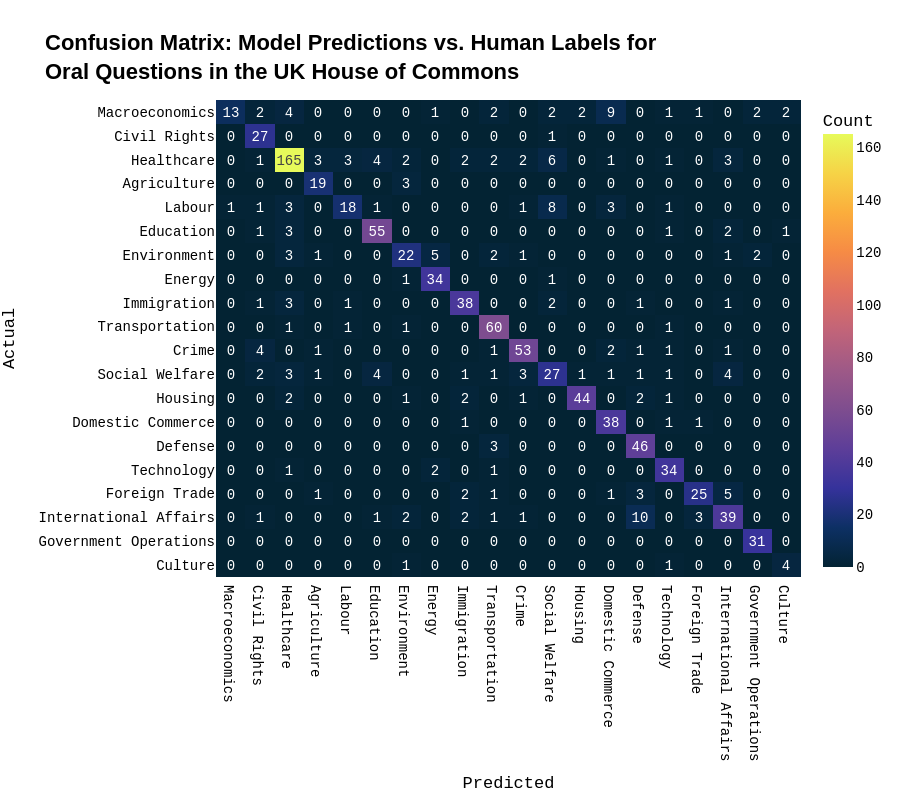
bert-base-multilingual-cased — sentiment model trained on Polish, English, Spanish, Dutch and German newspaper headlines
Available at: z-dickson/multilingual_sentiment_newspaper_headlines
Details
Language model trained to predict the sentiment of newspaper headlines in English, Polish, Spanish, Dutch and German.